Performance Benchmark Documentation
This documentation outlines the process for conducting performance benchmarks on Text Generation models within the platform. Performance benchmarks are crucial for evaluating the scalability and responsiveness of models under varying levels of user load.
Overview
Performance benchmarks are only applicable to Text Generation models that are deployed with VLLM, TGI, or OI_SERVE. These benchmarks help assess how the model performs under simulated real-world conditions.
Accessing Performance Benchmarks
To access the performance benchmark functionality:
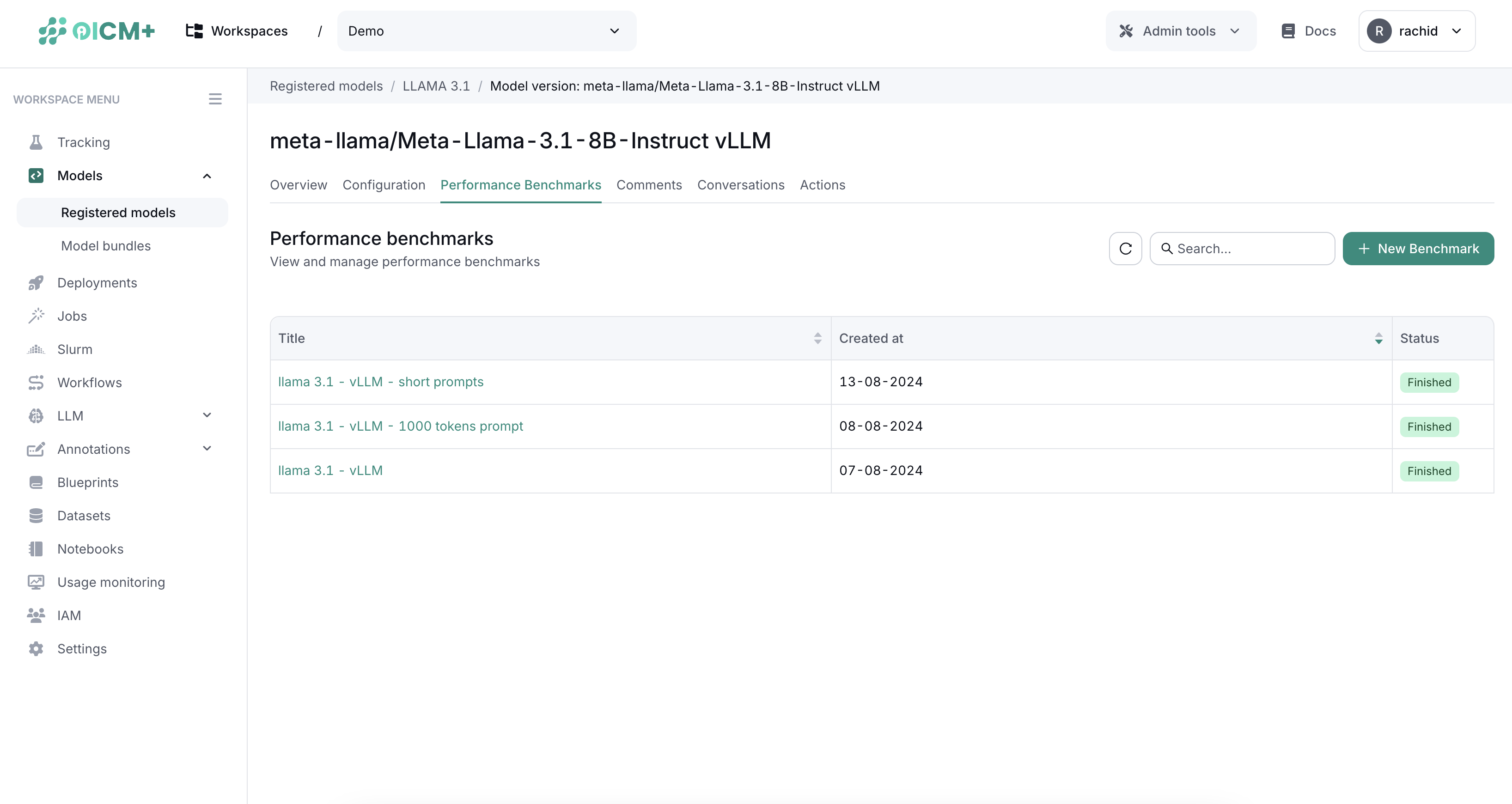
- Navigate to the specific model version you want to evaluate.
- Click on the Performance Benchmark tab. This tab displays a list of all previous benchmarks conducted on this model version.
Creating a New Benchmark
To create a new performance benchmark:
- Click on the New Benchmark button.
- You will be presented with a form to specify the benchmark parameters.
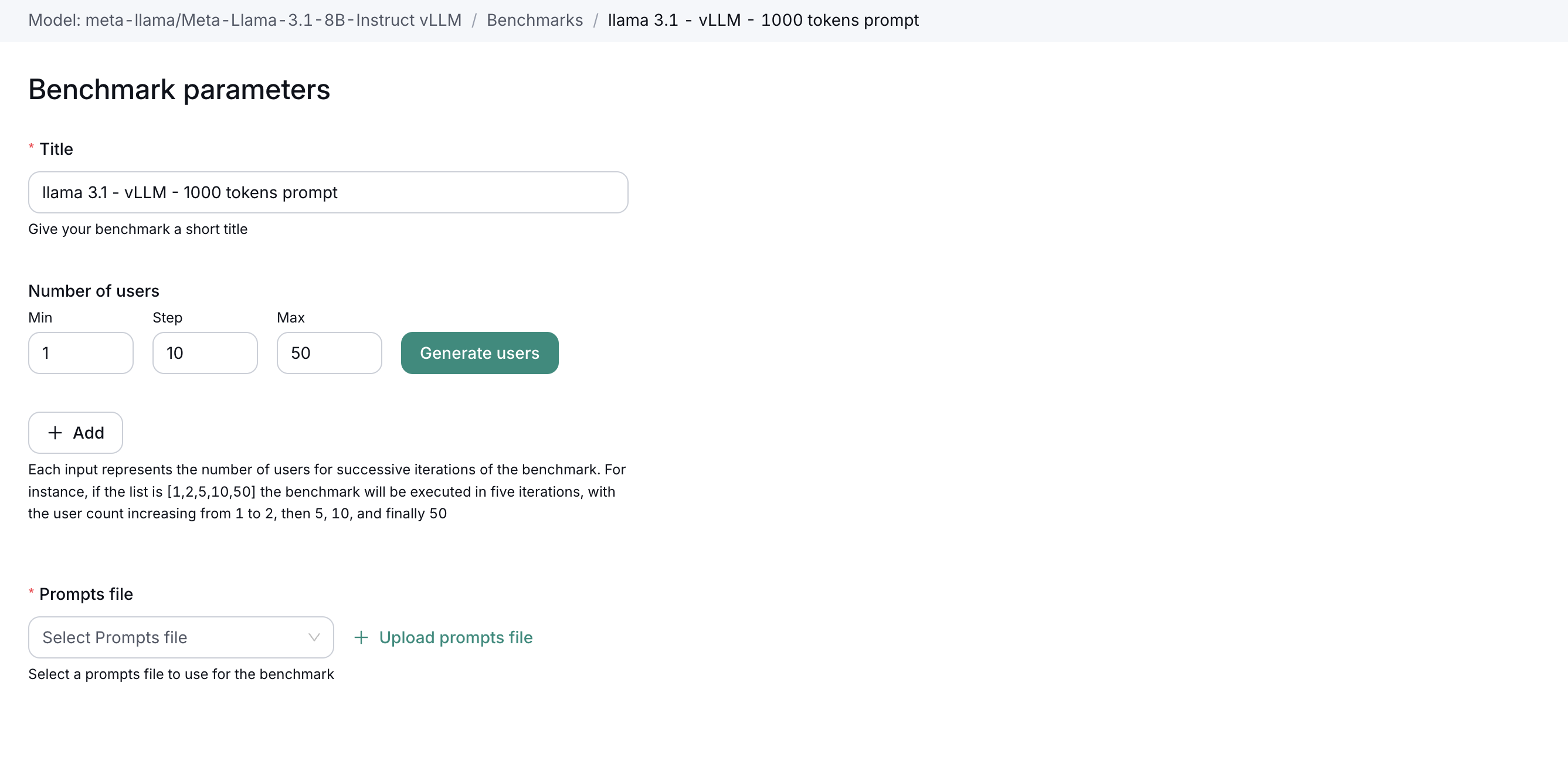
- Fill out the form with the following details:
- Title: Name of the benchmark for easy identification.
- Number of Concurrent Users: Specify how many concurrent users you want the model to handle during the test (e.g., 50, 100, 200).
- Prompt File: Upload the file containing prompts that will be used in the benchmark.
- Serving Parameters: Set parameters like temperature and top-k if applicable.
- Click Save and Run to initiate the benchmark.
Monitoring and Results
Once the benchmark is running:
- You can monitor the progress in real-time from the Results Dashboard.
- Upon completion, all results will be displayed on this dashboard, providing insights into the model's performance under test conditions.
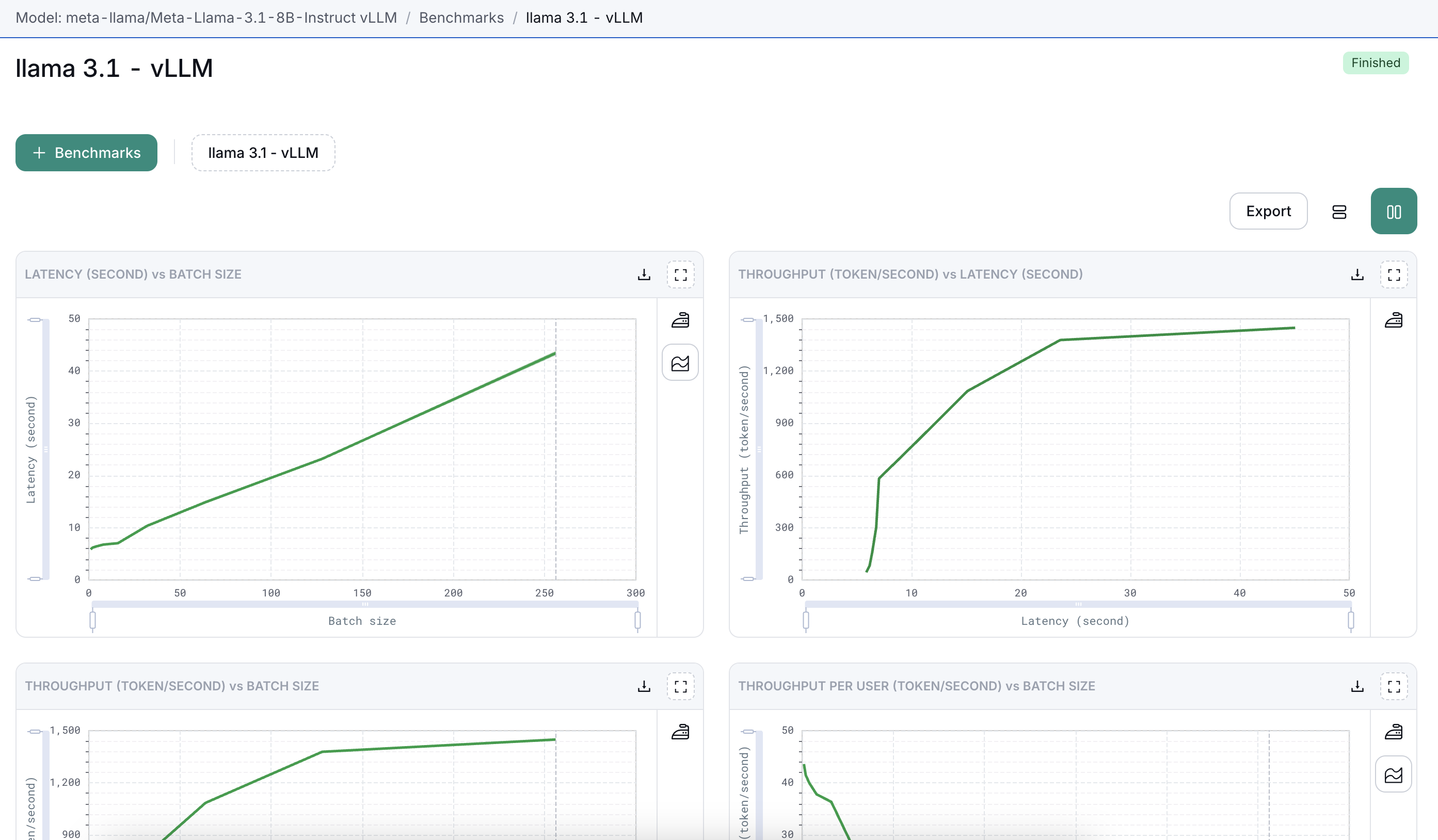
Exporting Results
Results from the performance benchmarks can be exported for further analysis or reporting:
- Export as PDF: For sharing and presentation purposes.
- Export as Excel: For data analysis and deeper insights.
These tools ensure that you can effectively use the performance data to optimize model configurations and improve overall system performance.