User Interface
The ASR Benchmark tab contains all the benchmarks configured for ASR models.
Package configuration
The main page contains all the benchmarks configured for ASR.
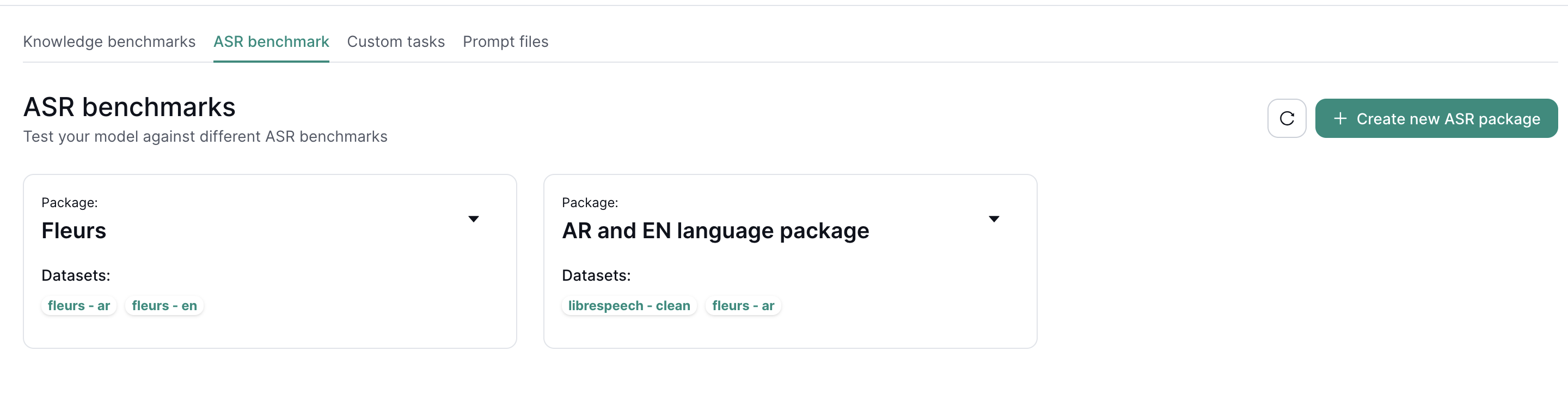
To create a new benchmark package select Create new ASR package.
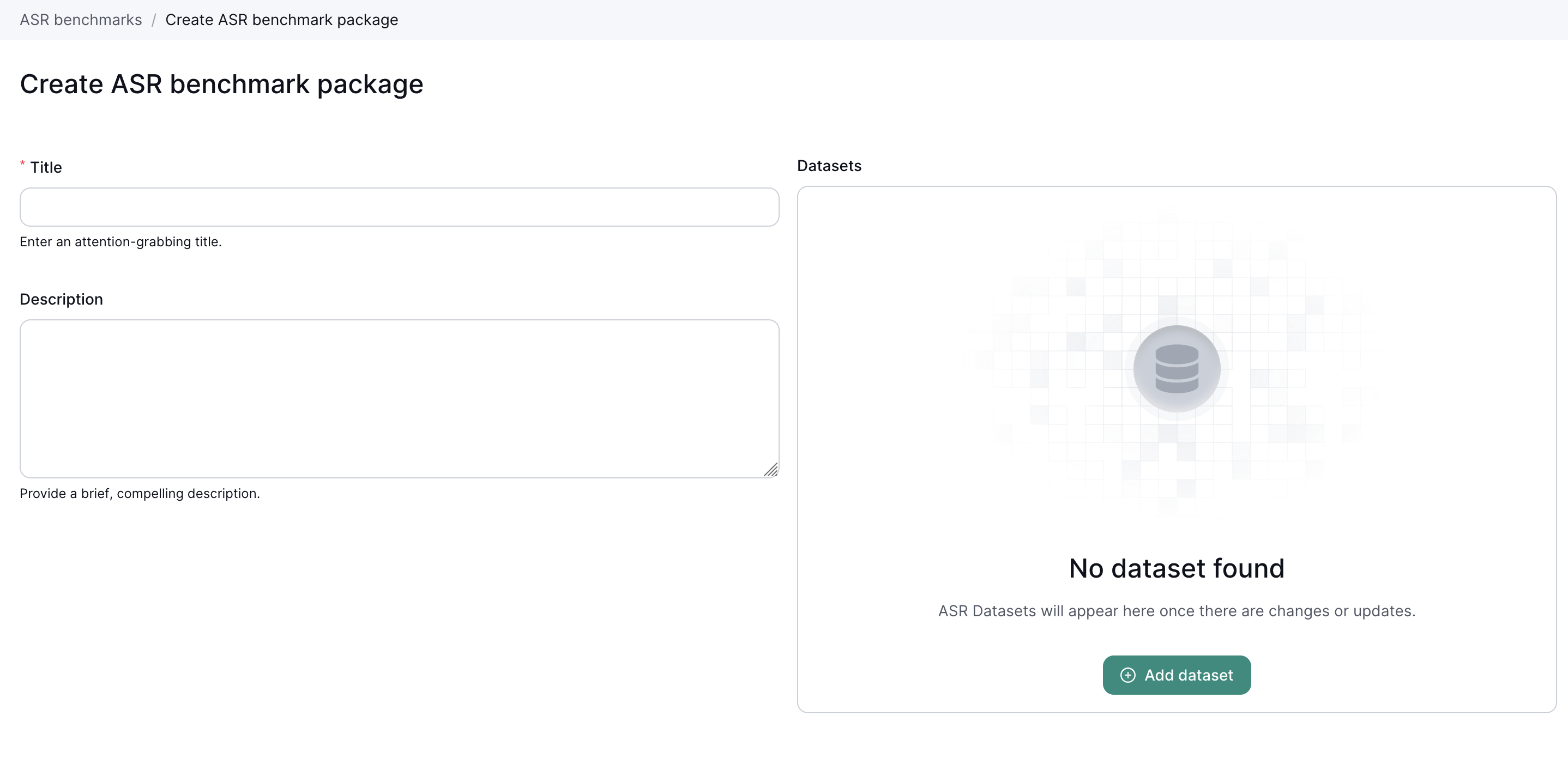
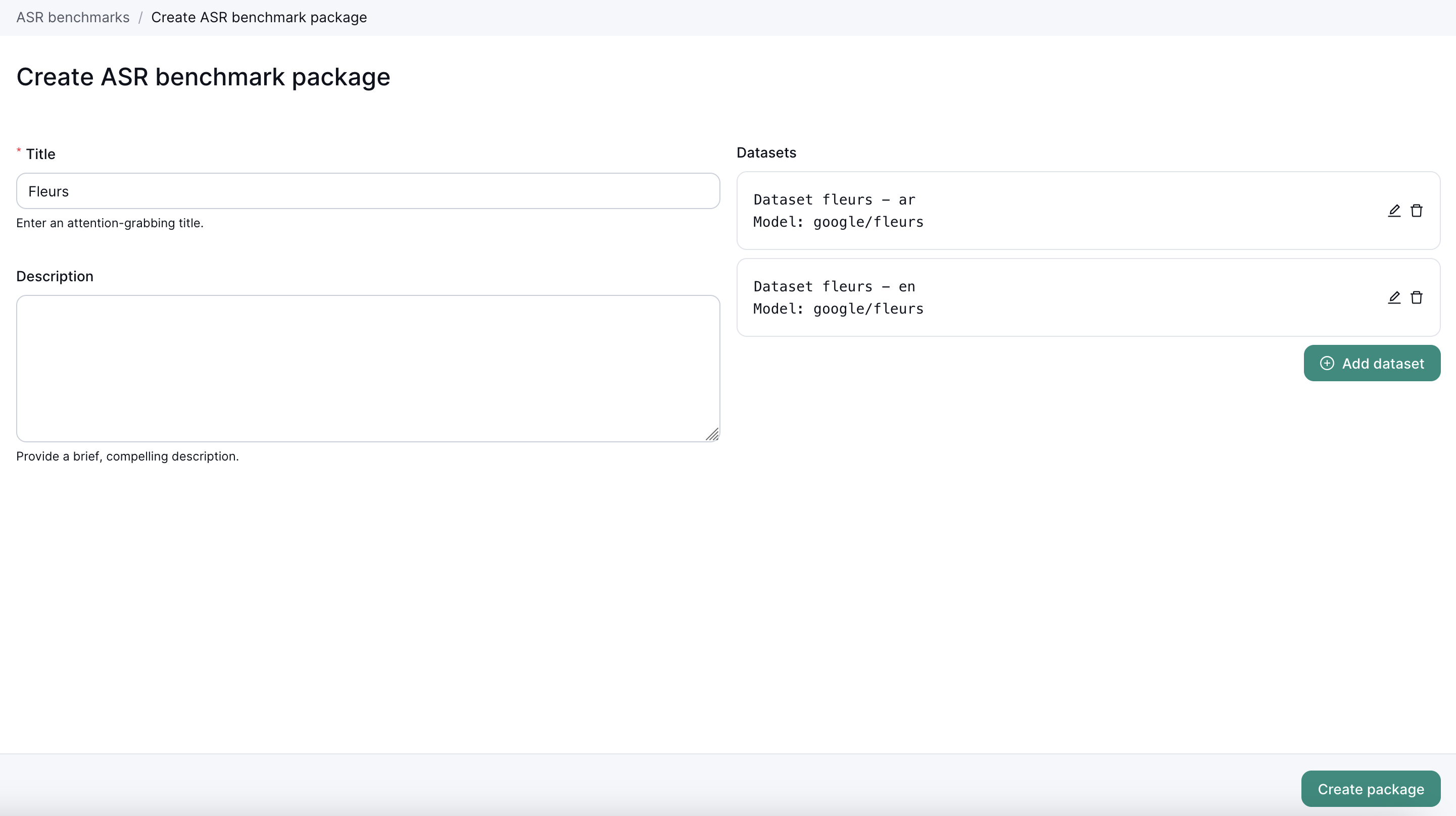
Each package is composed by multiple datasets, click Add dataset to add a new dataset to the package.
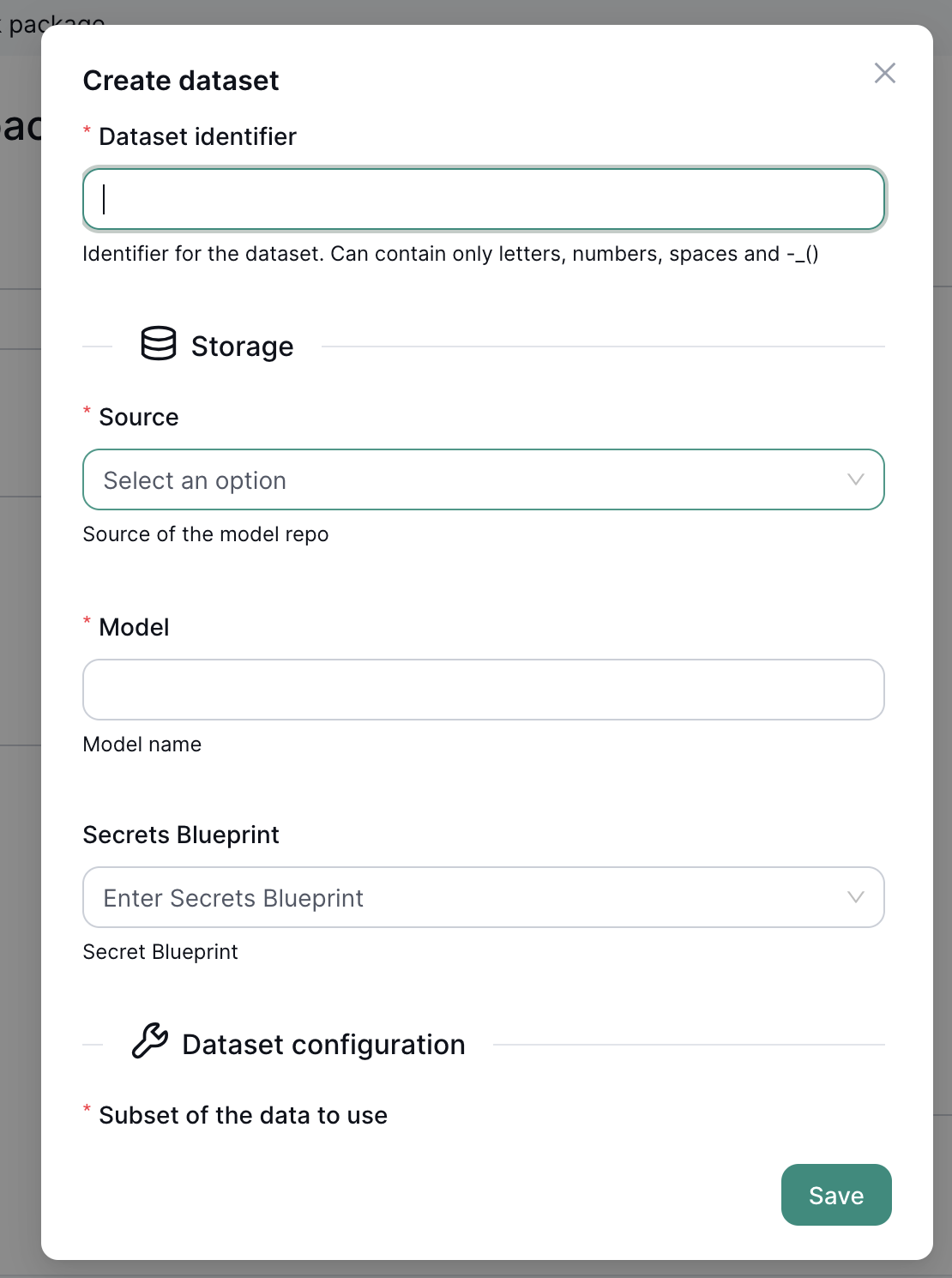
A dataset is made of
Dataset identifier: the identifier for this datasetSourceandModel: the audio dataset source- The dataset should contain a column with the audio to transcribe and the audio transcription
- You can find several datasets ready for use on HuggingFace Datasets
Dataset configuration: instructions on how to read the datasetSubset: the subset of the data to useSplit: the split (train, test or validation)AudioandTranscriptioncolumns
Normalizer: an optional normalizer applied to the transcribed and expected texts before comparing them
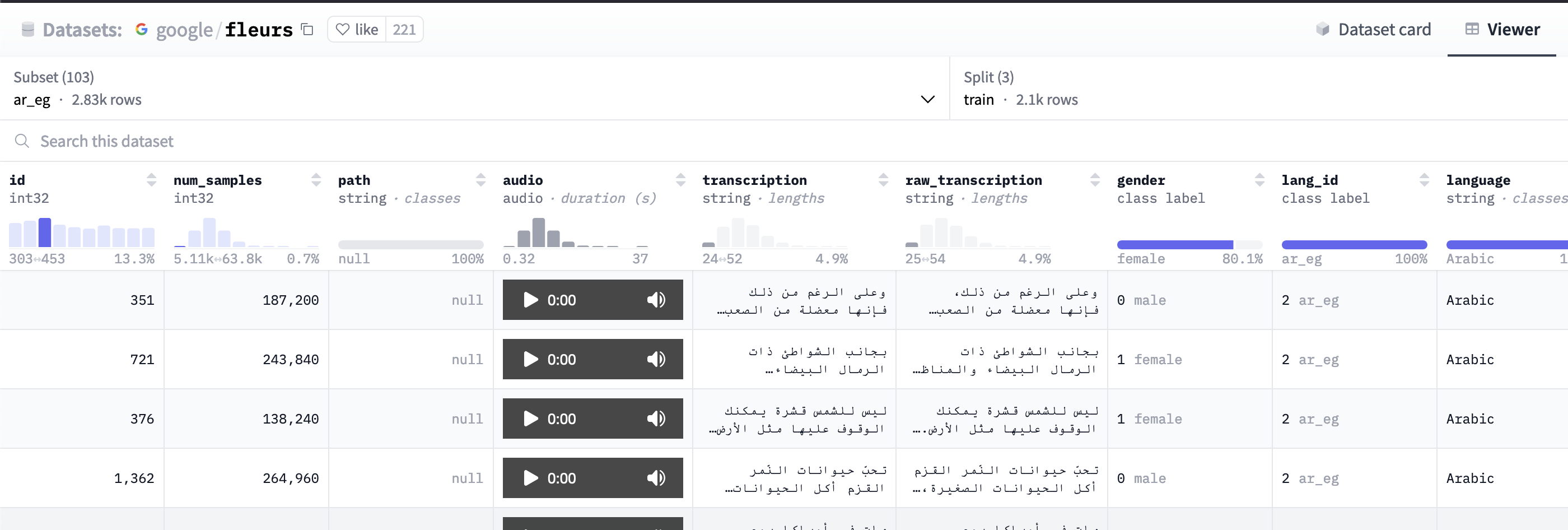
If using an HuggingFace dataset, you can check the available Subset and Split values from the Viewer tab
After adding all the datasets you want to test on, you can then save the package.
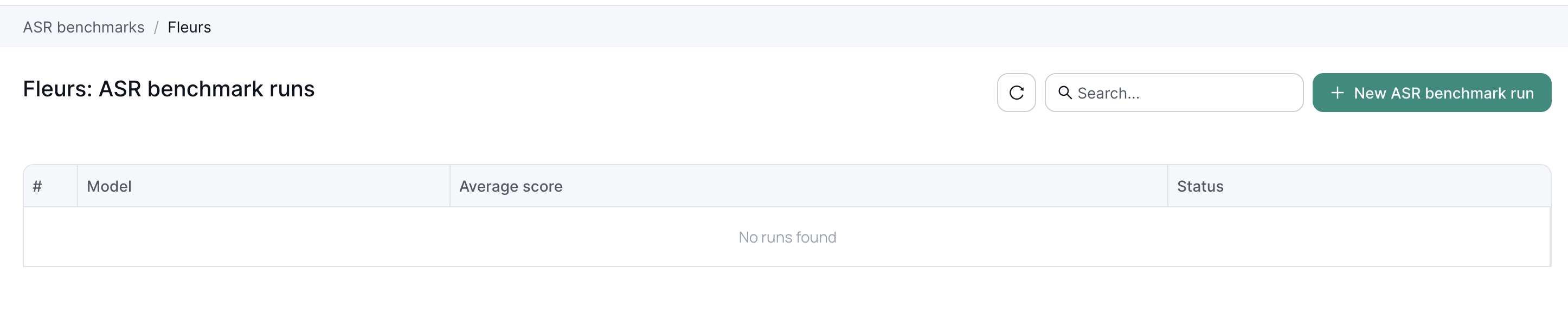
Running a benchmark
To run a benchmark select a package and then click New ASR Benchmark Run.
Fill-in the model you want to use, the necessary resources (GPU, CPU, ...) then click Run benchmark.
You can find some models to compare against on HuggingFace searching the tag automatic-speech-recognition.
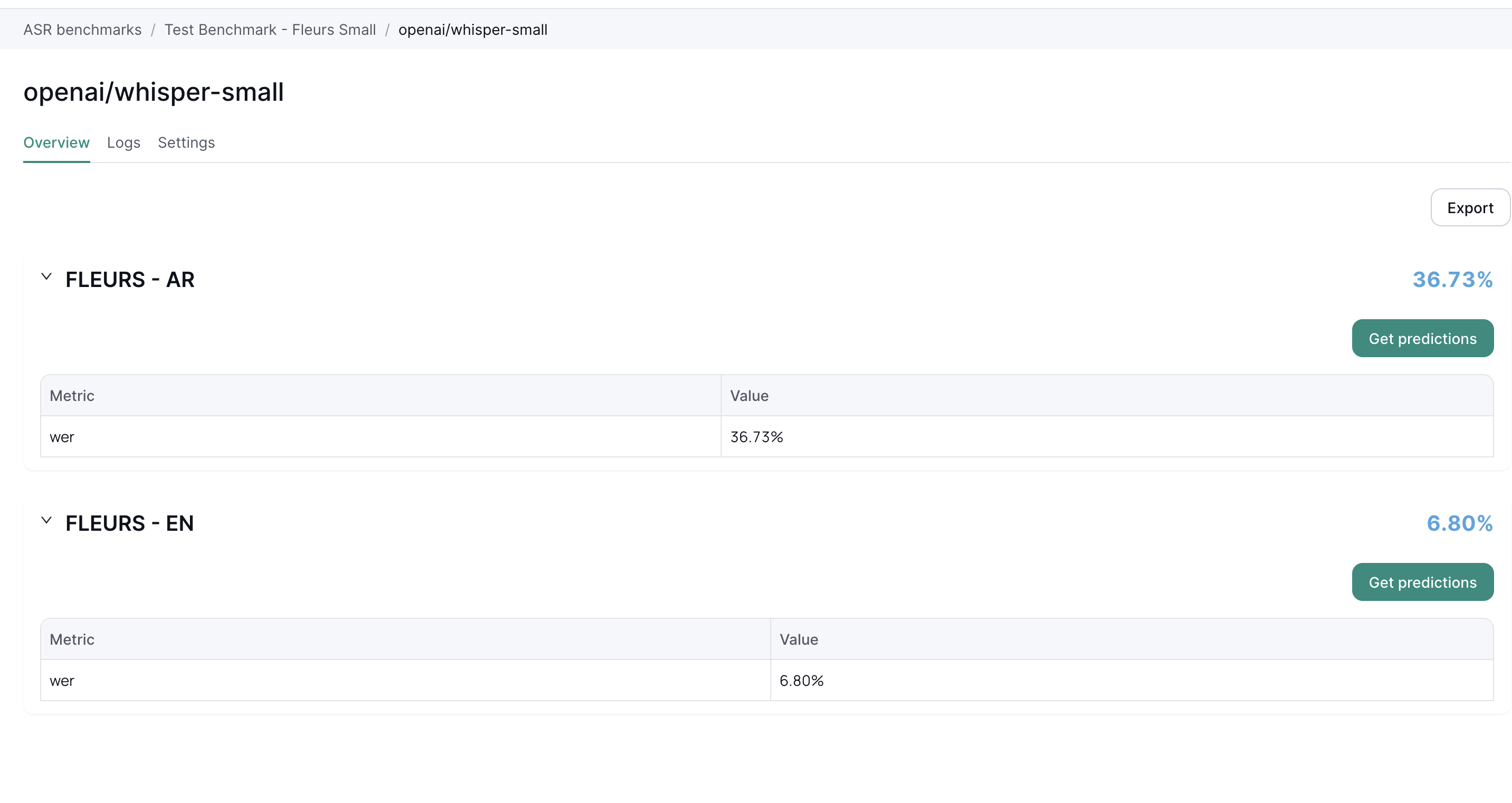
Checking the results
On the run page you can see all the models that ran with their aggregated score.

Click on an individual run to see the detailed results.