User Interface
Problems
After selecting Fine Tuning from the sidebar menu, you will be directed to the homepage for fine-tuning problems. Here, you can view the list of existing problems and create a new one.
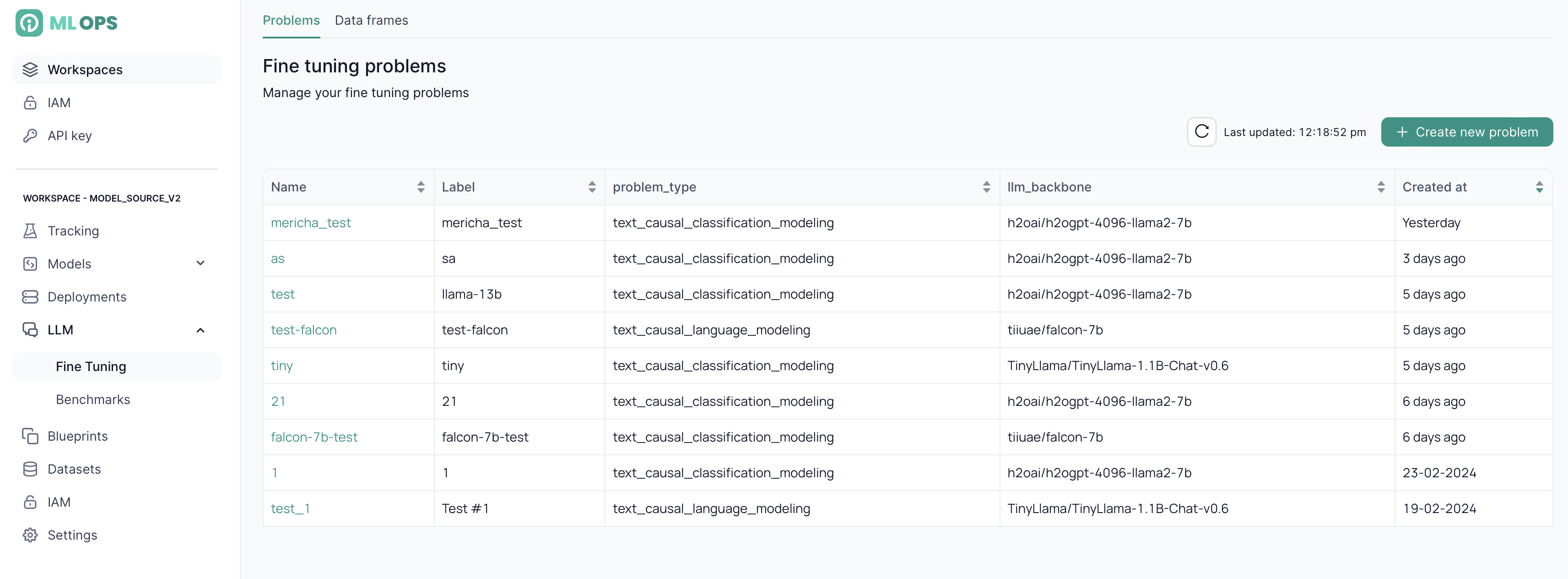
Create a new fine-tuning problem
By clicking on Create new problem, you can add a new fine-tuning problem.
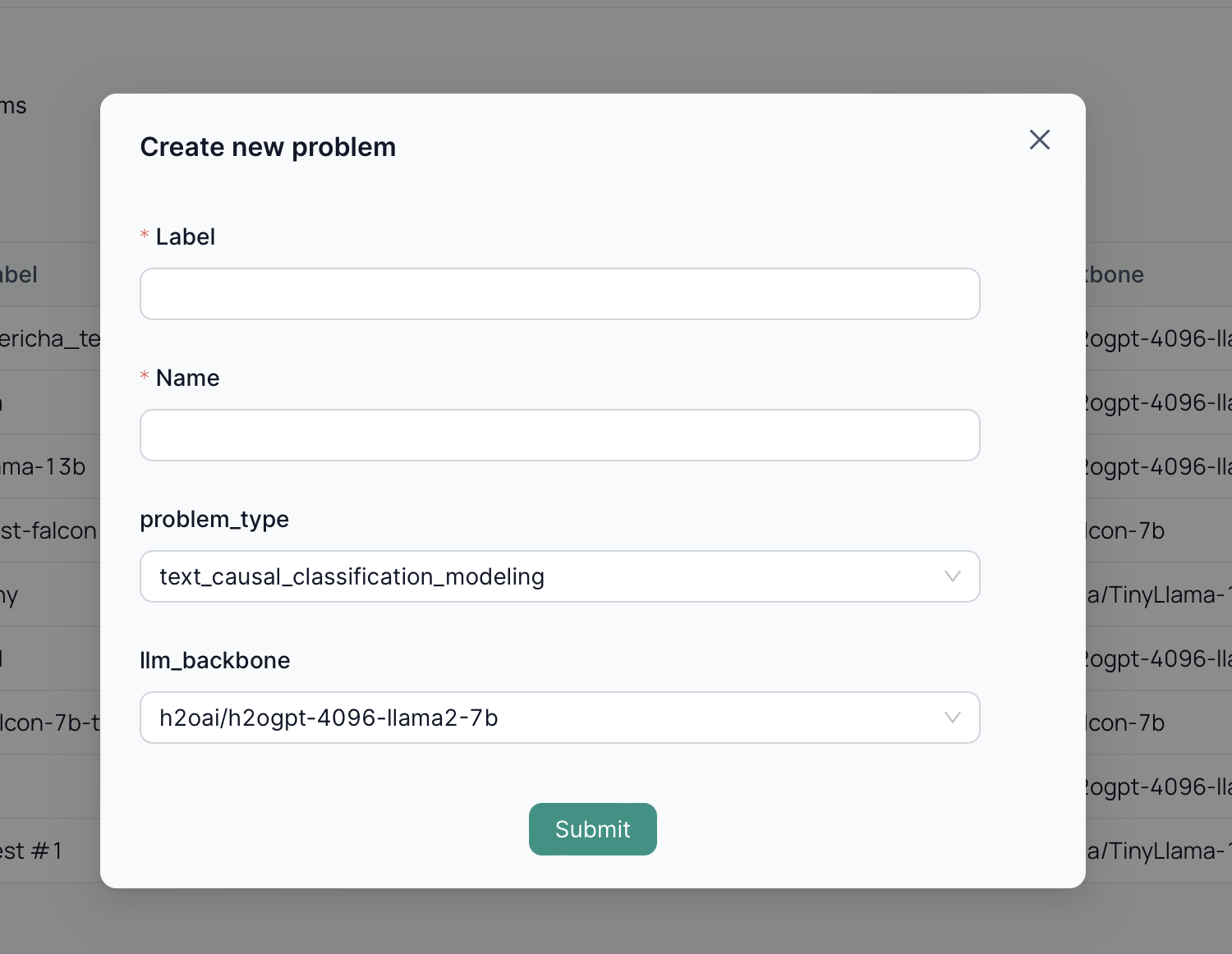
Once you enter the Label and Name for your fine-tuning job, you need to select the type of problem you want to address. Each task type has a specific purpose and dataset structure.
Currently, the platform supports five types of text-based fine-tuning tasks:
-
text_causal_classification_modeling-
Definition: Classifies text into predefined categories based on the causal relationship between input text and potential labels.
-
Use Case: Sentiment analysis (positive, negative, neutral), topic classification, intent detection (e.g., in chatbots).
-
Recommended Dataset Structure:
-
text: The input text to be classified. -
label: The corresponding category label.
-
json {"text": "This product is amazing!", "label": "positive"}, {"text": "I'm not sure how I feel about this.", "label": "neutral"} -
-
text_causal_language_modeling- Definition: Predicts the next word or phrase in a sentence based on the preceding context.
- Use Case: Text generation, autocompletion, content summarization.
- Recommended Dataset Structure:
- System prompt: instructions you want your model to follow while answering
- User prompt: example prompt that users potentially might ask
- Sample answer: sample answer that your chat model should produce
json {"system_prompt": "You are helpful assistant in OICM+ platform"}, {"sample_question": "Can I fine-tune the language models in OICM+?"}, {"sample_answer": "Definitely! Browse through the LLM section on the side menu, and choose Fine-tuning subcategory"} -
text_dpo_modeling(Direct Preference Optimization)-
Definition: Fine-tunes a language model to better align with human preferences, making it more helpful and harmless.
-
Use Case: Improving chatbot responses, generating safer content, refining recommender systems.
-
Recommended Dataset Structure:
prompt: The input text that elicits a response.chosen: The preferred response (more aligned with human preferences).rejected: An alternative, less preferred response.
json {"prompt": "Write a product description for a new smartphone.", "chosen": "This smartphone includes enhanced camera capabilities", "rejected": "This phone camera is better"} -
-
text_rlhf_modeling(Reinforcement Learning with Human Feedback)-
Definition: Combines reinforcement learning with human feedback to train a language model to generate text that is both high-quality and aligned with human values.
-
Use Case: Creating AI assistants that are helpful, harmless, and honest, generating creative content, writing code.
-
Recommended Dataset Structure:
prompt: The input instruction or context for the model.response: The model's generated text.reward: A numerical score indicating the quality of the response.
json {"prompt": "What is MLOps?", "response": "It's an abbreviation", "reward": 0}, {"prompt": "What is MLOps?", "response": "It is a field of AI that helps operationalize Machine Learning workflows", "reward": 1} -
-
text_seq_to_seq(Sequence-to-Sequence)-
Definition: Transforms input sequences of text into output sequences of text.
-
Use Case: Machine translation, text summarization, question answering.
-
Recommended Dataset Structure:
input_text: The source text to be transformed.target_text: The desired output text.
json {"input_text": "Bonjour!", "target_text": "Hello!"} {"input_text": "This is a long article to summarize.", "target_text": "This article discusses..."} {"input_text": "What is the capital of France?", "target_text": "Paris"} -
Before you start a new run you need to configure your fine-tuning problem
Prior to initiating the fine-tuning job, make sure you have the right configurations for your use-case.
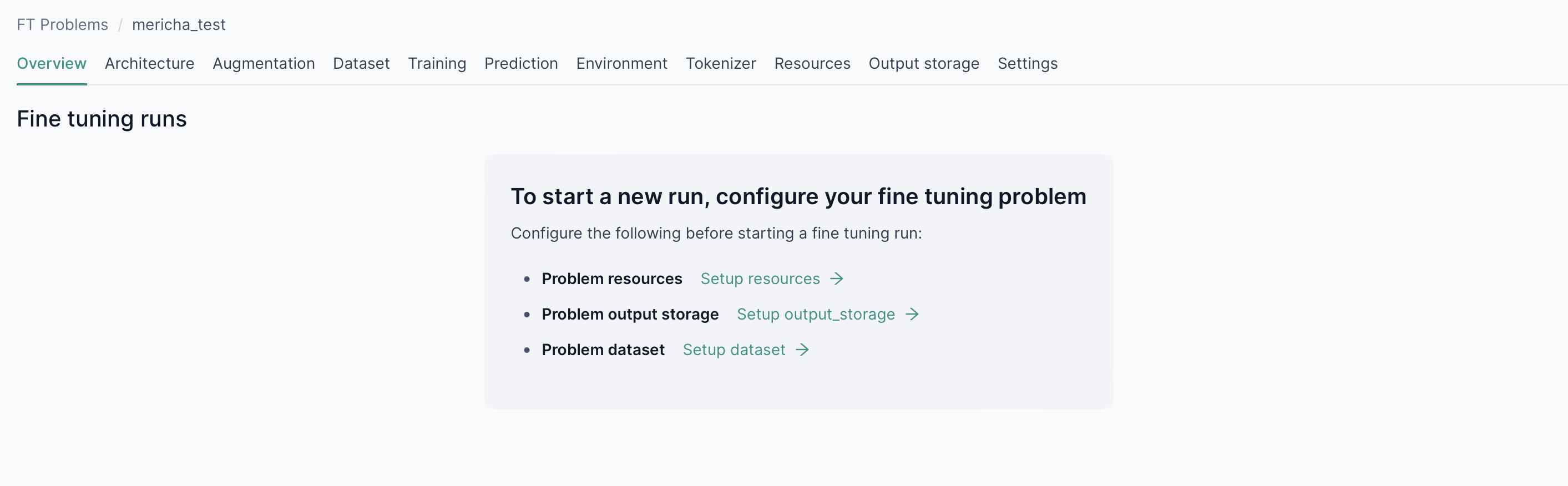
Start a new fine-tuning run
After configuring your fine-tuning problem, you can start a new run by clicking on Start new run. Once you've chosen your preferred instance type, you're ready to start your fine-tuning run.
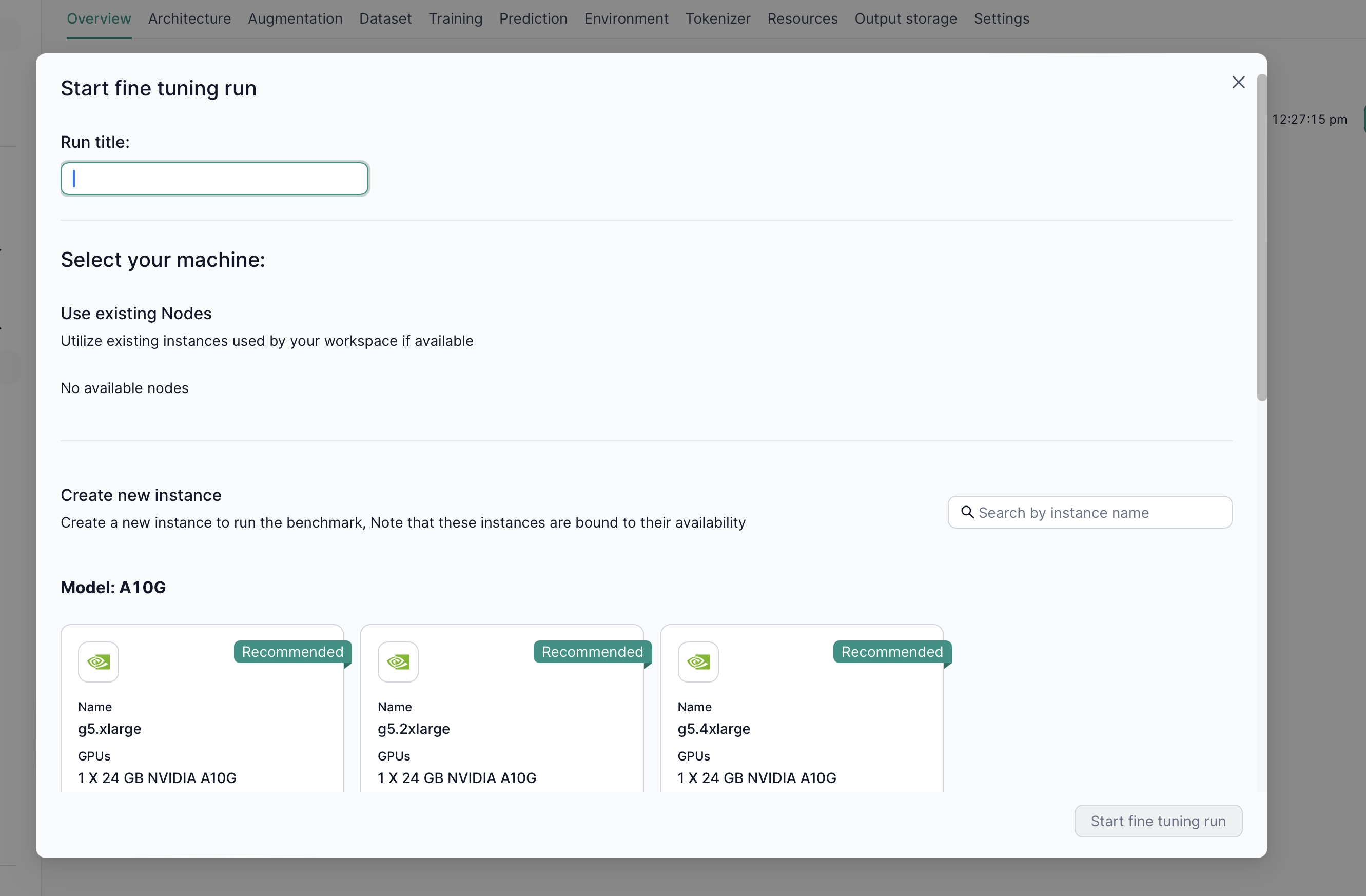
Navigate to the overview tab of your fine-tuning problem to check the status of your fine-tuning runs.
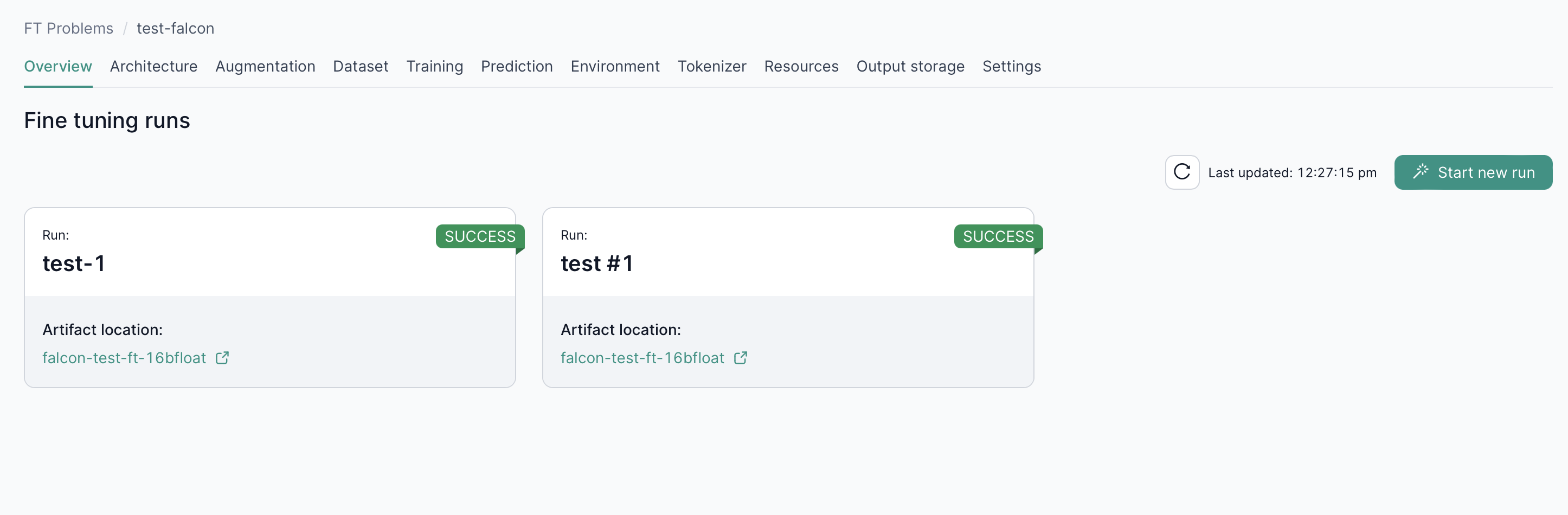
Monitoring
You can select a running instance to check the logs of the fine-tuning process.
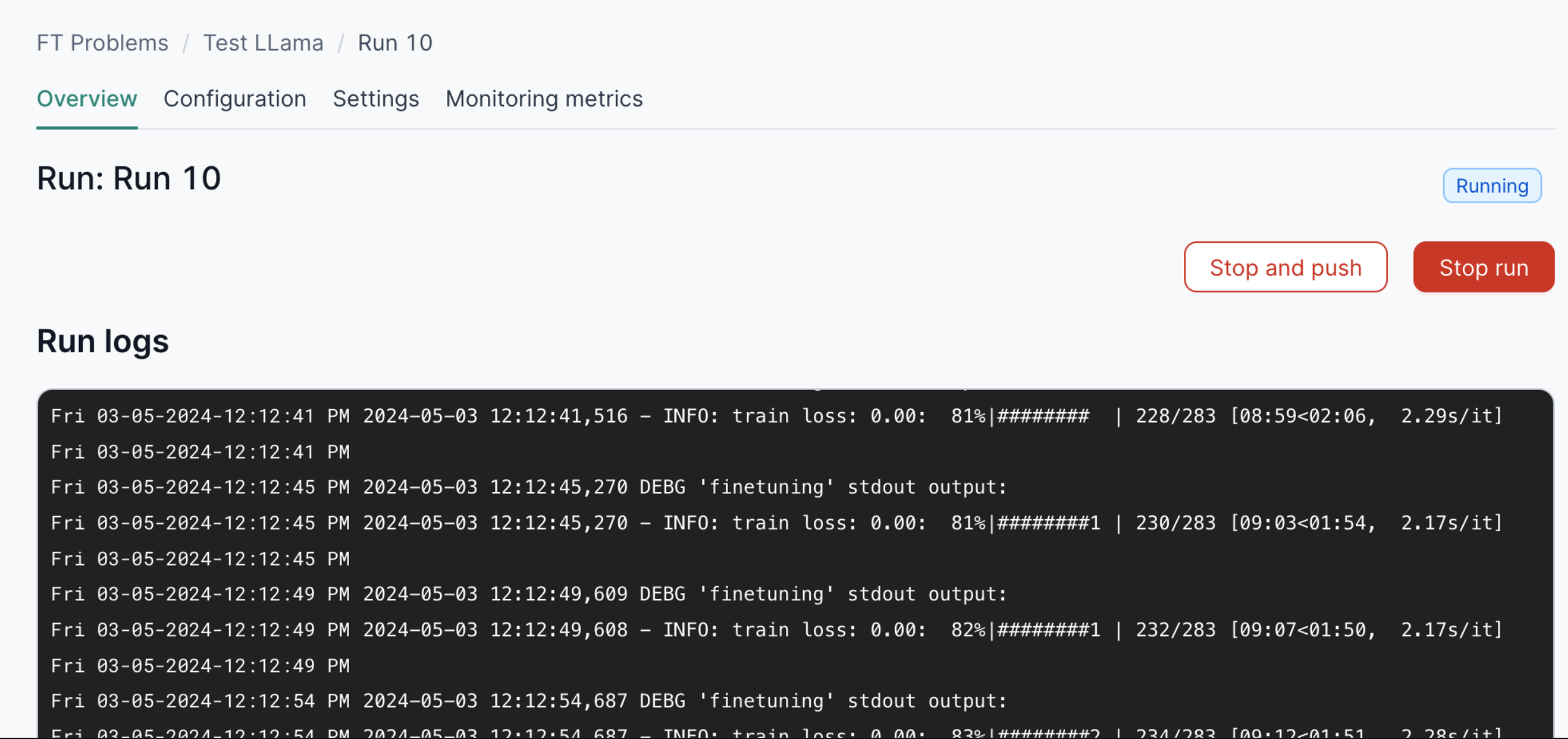
You can use the buttons to:
- Stop and push: stop the fine-tuning run and push the trained checkpoint to HuggingFace or Amazon S3. The run will not be stopped if the process has not generated a checkpoint yet.
- Stop run: stop the fine-tuning run and discard the trained model.
Data frame
To fine-tune your model, you need to use a specific dataset. That's why the Data frames section exist. After selecting Fine Tuning, navigate to the Data frames tab. By default, you will see all the existing data frames.
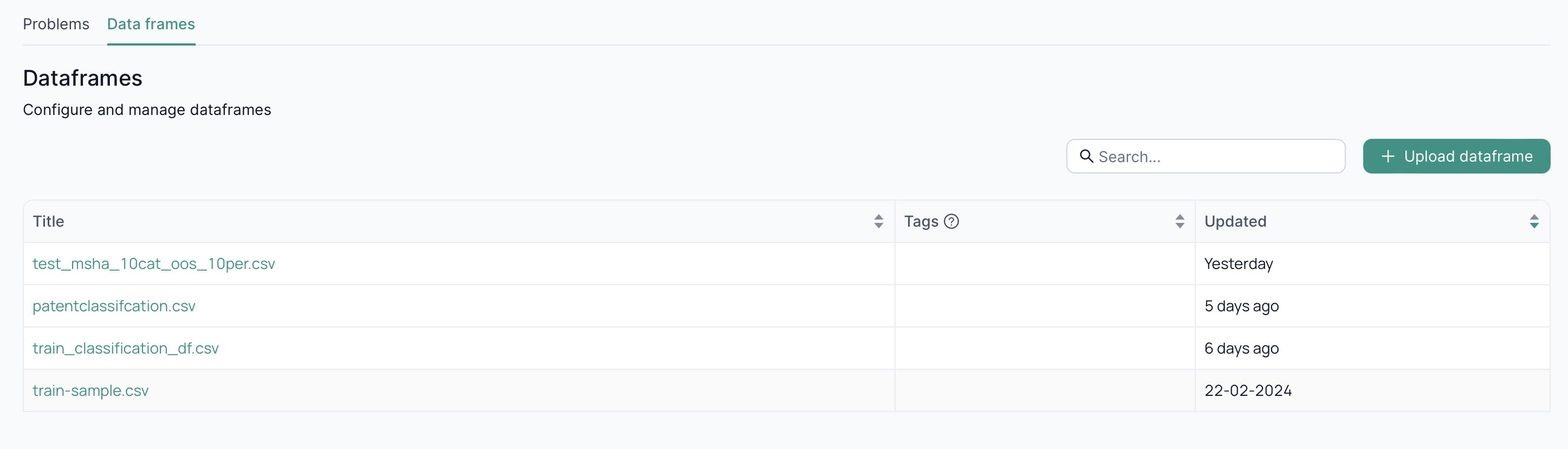
By clicking on Upload dataframe, you can upload any file you need for your future fine-tuning problems.