Model Version Configuration
Configuring a model version involves setting up several key aspects that determine how the model is sourced, served, and managed. Below are the sections typically included in the model version configuration interface.
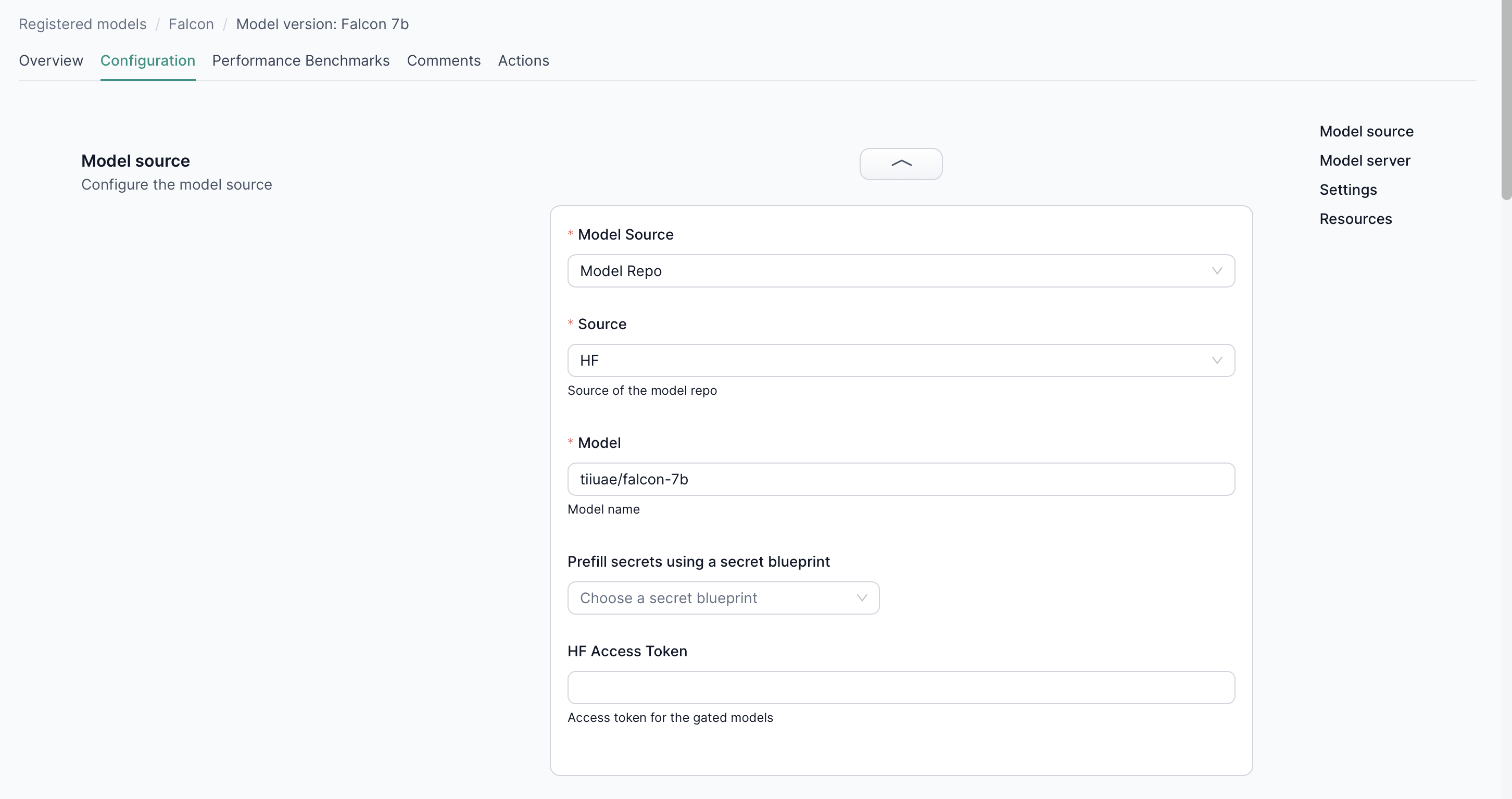
Model Source
Specify the origin of the model to ensure the correct source is utilized during deployment:
- Tracked: Utilize a model tracked within our platform's tracking module. Select the run associated with the desired model.
- Model Repo: For transformer-based models, choose between:
- Huggingface: Provide the model ID from Huggingface.
- S3 Bucket: Specify the bucket, folder, and provide S3 credentials.
- External: Use a model bundle. More details can be found on the Model Bundle Documentation.
- Docker Image: Deploy using a custom Docker image. Further information is available on the Docker Image Documentation.
Model Server
Choose the serving framework suitable for the model type along with specific parameters:
- MLFLOW: It is used as the default inference server, it's the best choice for deploying the classical ML Models.
- TGI: A Rust, Python and gRPC server for text generation inference. Used in production at HuggingFace to power Hugging Chat, the Inference API and Inference Endpoint. One of the best choices to deploy the text generation models, but not all models are supported.
- VLLM: vLLM is a Python library that also contains pre-compiled C++ and CUDA binaries. Which is considered as one of the best choice to deploy the text generation models, but not all models are supported.
- OI Serve (Open Innovation Serve): OI Serve is OpenInnovation serving library built on top of RayServe. The main function of OI Serve is to be able to deploy all the LLMs pipeline. So, it's the best choice to deploy your text generation model if it's not supported in vLLM or TGI. The performance of OI Serve in terms of throughput and latency is not the same as TGI or vLLM because the main function of it is to deploy all the LLMs, hence there's no custom logic for a specific model. The following pipelines are supported and the other pipelines are being developed:
- Text Generation
- Sequence Classification
- Translation, If the user doesn't add the source and target language, the default translation pipeline will be launched and the source and target languages are set based on the default model configurations.
- Automatic Speech Recognition (ASR)
- Text To Speech (TTS), By default, OI Serve deploys the TTS model with the default text-to-speech pipeline, unless the model as a custom loader. For now OI Server supports (1) custom loader for these models families:
- 1- parler-tts
- Text To Image
- Text-Embedding-Inference: Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for the most popular models, including FlagEmbedding, Ember, GTE and E5. The following model types are supported:
- Sequence Classification
- Embeddings
- Re-Ranking
Each serving option requires different parameters, which need to be specified during configuration.
General Settings
General settings to define operational characteristics of the model:
- Name: Assign a name to the model version.
- Tags: Apply tags for easier categorization and searchability.
- Number of Replicas: Specify how many instances of the model should be deployed to handle the load.
Resources
Define the computational resources needed for the model to perform optimally:
- GPU: Specify the GPU resources required.
- Memory: Allocate the necessary memory.
- CPU: Define the CPU resources needed.
- Storage: Indicate the amount of storage required.
Chat templates
If you're configuring an LLM and you're planning to use the chat inference, then you have to add a chat template in the model version configurations only if you're model family is not supported by default in the OI platform. The supported families are:
- LLAMA 2
- LLAMA 3
- Falcon
- Yi
- Mistral
- Aya-23
If you can't provide the chat template for your model, you still can use the completion inference.
Note: The chat template must be a valid jinja with one variable
messagesandadd_generation_prompt. This is an example of theCohereForAI/aya-23chat template that is natively supported in the OI Platform:
<BOS_TOKEN>
{% if messages[0]['role'] == 'system' %}
{% set loop_messages = messages[1:] %}
{% set system_message = messages[0]['content'] %}
{% else %}
{% set loop_messages = messages %}
{% set system_message = false %}
{% endif %}
{% if system_message != false %}
{{ '<|START_OF_TURN_TOKEN|><|SYSTEM_TOKEN|>' + system_message + '<|END_OF_TURN_TOKEN|>' }}
{% endif %}
{% for message in loop_messages %}
{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}
{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}
{% endif %}
{% set content = message['content'] %}
{% if message['role'] == 'user' %}
{{ '<|START_OF_TURN_TOKEN|><|USER_TOKEN|>' + content.strip() + '<|END_OF_TURN_TOKEN|>' }}
{% elif message['role'] == 'assistant' %}
{{ '<|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>' + content.strip() + '<|END_OF_TURN_TOKEN|>' }}
{% endif %}
{% endfor %}
{% if add_generation_prompt %}
{{ '<|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>' }}
{% endif %}
- Only models hosted on Huggingface are supported for now.
- We use the model id and your secrets reference from the model version form.