Inference Gateway Guide
Overview
The Inference Gateway feature allows you to create and manage inference channels for your AI/ML models through REST APIs. It provides secure token-based authentication and supports various model types including LLMs, computer vision, speech processing, and classical ML models. The gateway simplifies model deployment by handling the complexities of serving while allowing you to focus on building applications.
Setting Up an Inference Gateway
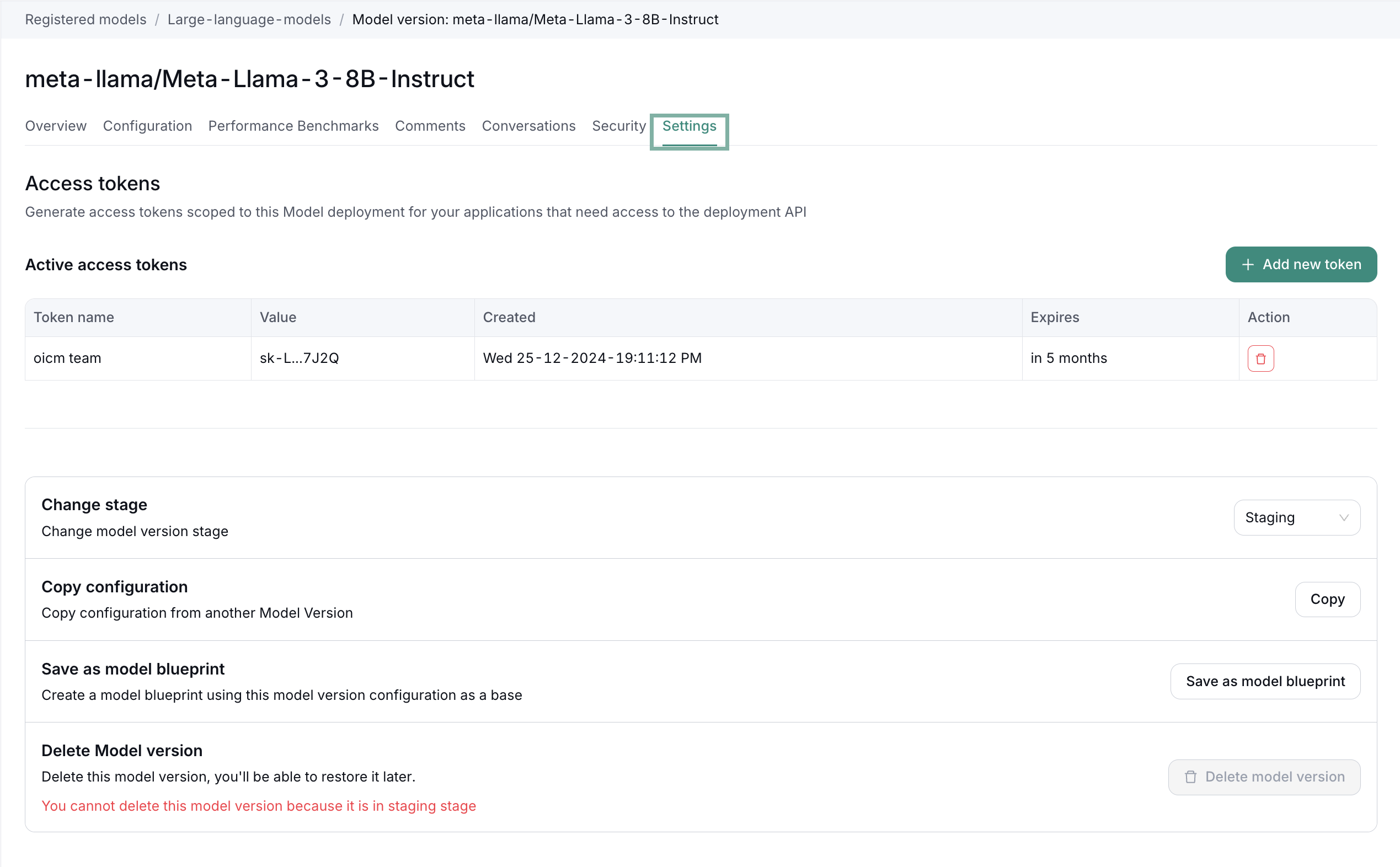
Step 1: Access Model Settings
- Navigate to your registered model in the workspace
- Go to the "Settings" tab in the model version page
- Look for the "Access tokens" section
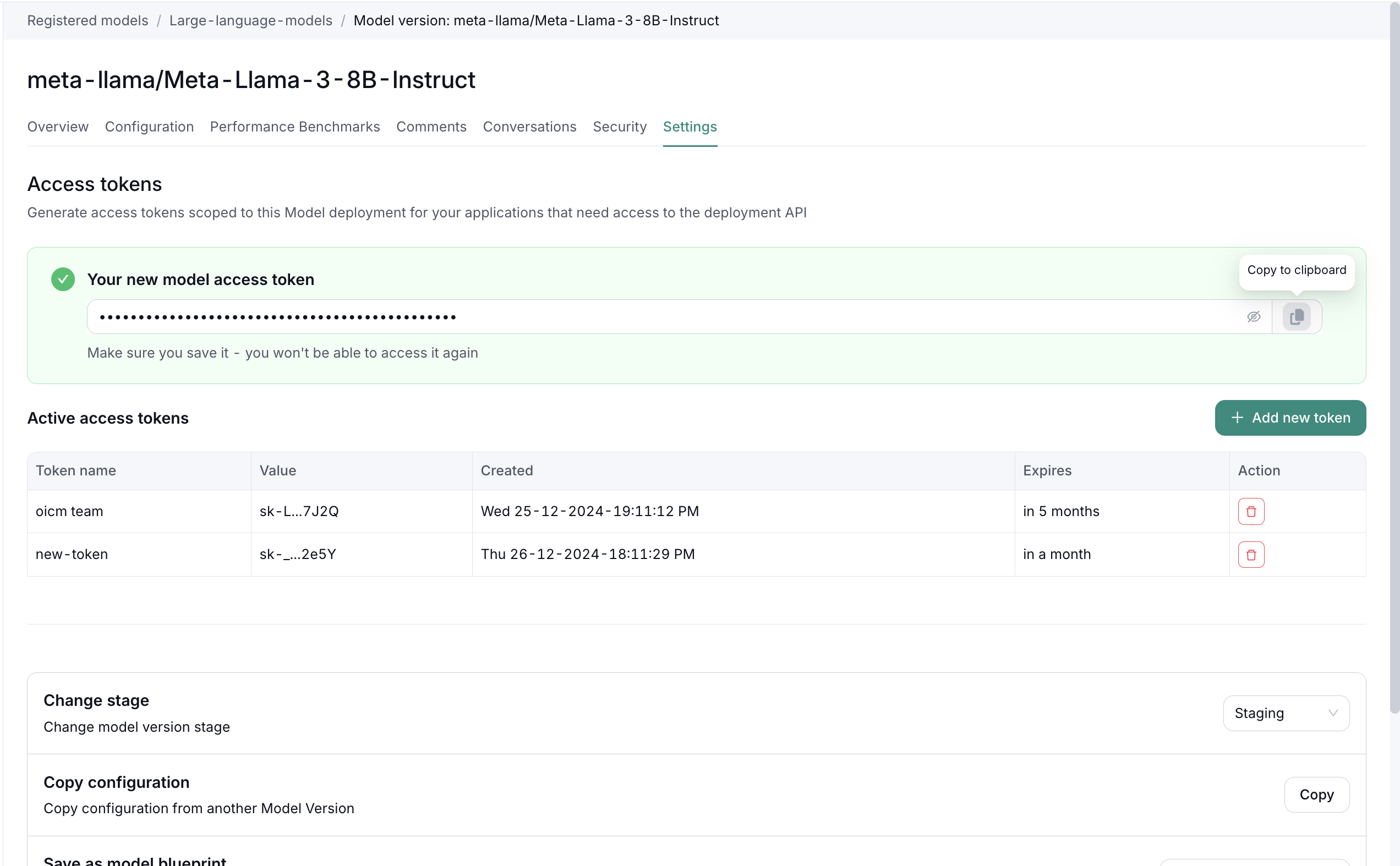
Step 2: Generate Access Token
- Click the "+ Add new token" button
- Provide a name for your token (e.g., "new-token")
- The system will generate a new access token
- Important: Make sure to save the token immediately - you won't be able to access it again
Step 3: Configure Inference Settings
The inference gateway provides built-in support for several AI tasks. When you select your deployment type, the system automatically generates the appropriate inference code with optimized payload structures. Supported tasks include text generation and chat, sequence classification, speech recognition, text-to-speech conversion, image generation, translation, reranking and embedding generation.
Below example shows how to use the API access key and generate the code snippet for API calls in Python applications for a Large Language Model deployment.
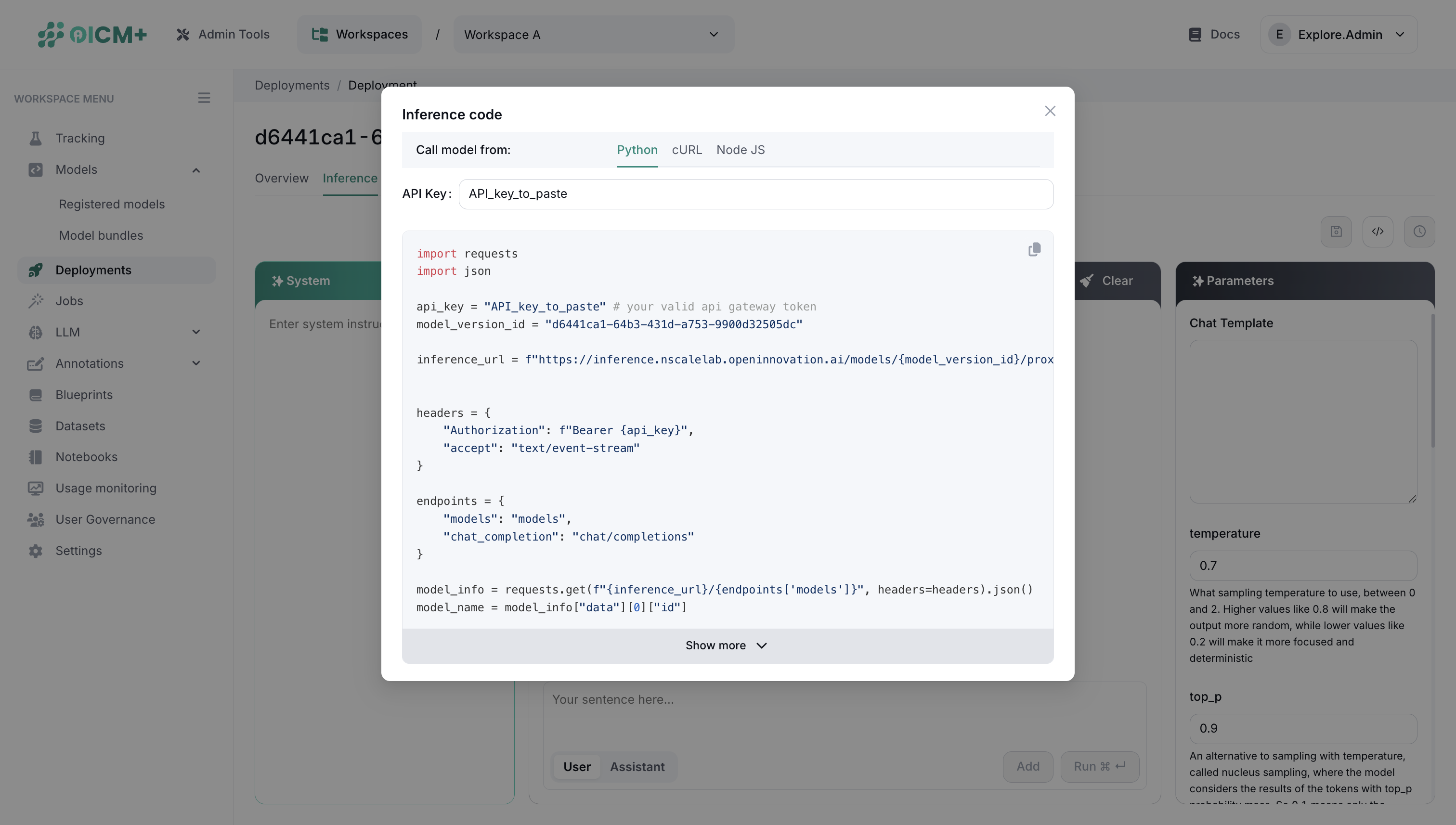
Step 4: Making API Calls
To make inference calls, you'll need:
- Your API token
- The model version ID
- The appropriate endpoint for your use case
Please, refer to the next section where detailed examples of API calls are mentioned for various AI tasks.
Advanced Configuration
Temperature and Top-p Settings
- Temperature (default: 0.7): Controls randomness in the output. Higher values (e.g., 0.8) make the output more random, while lower values (e.g., 0.2) make it more focused and deterministic.
- Top-p (default: 0.9): An alternative to sampling with temperature, also known as nucleus sampling. The model considers the tokens with top_p probability mass.
Request Timeout
- Default timeout: 120 seconds
- Custom timeout can be set using the
OICM-Request-Timeoutheader:
Token Management
- Tokens can be created with different expiration periods
- Active tokens can be viewed and managed in the Settings page
- Tokens can be revoked at any time using the delete action
- The platform supports multiple active tokens for different applications or use cases
Inference Payload Examples
2.1 Text Generation
Endpoint
POST <API_HOST>/models/<model_version_id>/proxy/v1/chat/completions
Usage example
import requests
import json
api_key = <api_key>
model_version_id = <model_version_id>
base_url = <base_url> # example: https://inference.develop.openinnovation.ai
inference_url = (
f"${base_url}/models/{model_version_id}/proxy/v1/chat/completions"
)
headers = {"Authorization": f"Bearer {api_key}", "accept": "text/event-stream"}
payload = {
"inputs": "What is Deep Learning?",
"max_new_tokens": 200,
"do_sample": False,
"stream": True,
}
chat_response = requests.post(
f"{inference_url}", headers=headers, json=payload, stream=True
)
for token in chat_response.iter_lines():
try:
string_data = token.decode('utf-8')
string_data = string_data[6:]
json_data = json.loads(string_data)
content = json_data['choices'][0]['delta']['content']
print(content, end="", flush=True)
except:
pass
Chat Template
You can provide a custom chat template in the payload. If so, the OI platform will use this template to format the chat history before sending it to the LLM.
Note: the chat template should be a valid jinja that has only one variable messages
Example
{
"messages": [
{"role": "system", "content": "Be friendly"},
{"role": "user", "content": "What's the capital of UAE?"},
{"role": "assistant", "content": ""}
],
"chat_template": '''
{% if messages[0]['role'] == 'system' %}
{% set loop_messages = messages[1:] %}
{% set system_message = messages[0]['content'] %}
{% else %}
{% set loop_messages = messages %}
{% set system_message = '' %}
{% endif %}
{% for message in loop_messages %}
{% if loop.index0 == 0 %}
{{ system_message.strip() }}
{% endif %}
{{ '\n\n' + message['role'] + ': ' + message['content'].strip().replace('\r\n', '\n').replace('\n\n', '\n') }}
{% if loop.last and message['role'] == 'user' %}
{{ '\n\nAssistant: ' }}
{% endif %}
{% endfor %}
'''
}
2.2 Text completion - VLLM
Endpoint
POST <API_HOST>/models/<model_version_id>/proxy/v1
Usage example
import requests
import json
api_key = <api_key>
model_version_id = <model_version_id>
base_url = <base_url>
inference_url = f"${base_url}/models/{model_version_id}/proxy/v1"
headers = {
"Authorization": f"Bearer {api_key}",
"accept": "text/event-stream"
}
endpoints = {
"models": "models",
"chat_completion": "chat/completions"
}
model_info = requests.get(f"{inference_url}/{endpoints['models']}", headers=headers).json()
model_name = model_info["data"][0]["id"]
payload = {
"model": model_name,
"messages": [
{
"role": "system",
"content": "You are a helpful assisant"
},
{
"role": "user",
"content": "describe gravity to 6-year old child in 50 words"
# "content": "tell me a long story"
}
],
"temperature": 0.9,
"top_p": 0.7,
"max_tokens": 1000,
"stream": True
}
chat_response = requests.post(f"{url}/{endpoints['chat_completion']}", headers=headers, json=payload, stream=True)
for token in chat_response.iter_lines():
try:
string_data = token.decode('utf-8')
string_data = string_data[6:]
json_data = json.loads(string_data)
content = json_data['choices'][0]['delta']['content']
print(content, end="", flush=True)
except:
pass
2.3 Text completion - TGI
Endpoint
POST <API_HOST>/models/<model_version_id>/proxy/v1
Usage example
import requests
import json
api_key = <api_key>
model_version_id = <model_version_id>
base_url = <base_url>
inference_url = f"${base_url}/models/{model_version_id}/proxy/v1"
headers = {
"Authorization": f"Bearer {api_key}",
"accept": "text/event-stream"
}
endpoints = {
"models": "models",
"chat_completion": "chat/completions"
}
model_info = requests.get(f"{inference_url}/{endpoints['models']}", headers=headers).json()
model_name = model_info["data"][0]["id"]
payload = {
"model": model_name,
"messages": [
{
"role": "system",
"content": "You are a helpful assisant"
},
{
"role": "user",
"content": "describe gravity to 6-year old child in 50 words"
# "content": "tell me a long story"
}
],
"temperature": 0.9,
"top_p": 0.7,
"max_tokens": 1000,
"stream": True
}
chat_response = requests.post(f"{url}/{endpoints['chat_completion']}", headers=headers, json=payload, stream=True)
for token in chat_response.iter_lines():
try:
string_data = token.decode('utf-8')
string_data = string_data[6:]
json_data = json.loads(string_data)
content = json_data['choices'][0]['delta']['content']
print(content, end="", flush=True)
except:
pass
2.4 Sequence Classification
Endpoint
POST <API_HOST>/models/<model_version_id>/proxy/classify
Usage example
import requests
api_key = <api_key>
model_version_id = <model_version_id>
base_url = <base_url>
inference_url = (
f"${base_url}/models/{model_version_id}/proxy/v1/classify"
)
headers = {"Authorization": f"Bearer {api_key}"}
payload = {
"inputs": "this is good!",
}
response = requests.post(f"{inference_url}", headers=headers, json=payload)
response.json(),
curl: `curl -X POST "${inference_url}" \
-H "Authorization: Bearer ${api_key}" \
-H "Content-Type: application/json" \
-d '{
"inputs": "this is good!"
}'
Response Format
{
"classification": [
{
"label": "admiration",
"score": 0.7764764428138733
},
{
"label": "excitement",
"score": 0.11938948929309845
},
{
"label": "joy",
"score": 0.04363647475838661
},
{
"label": "approval",
"score": 0.012329215183854103
},
{
"label": "gratitude",
"score": 0.010198703035712242
},
...
]
}
2.5 Automatic Speech Recognition
Endpoint
POST <API_HOST>/models/<model_version_id>/proxy/transcript
Usage example
import requests
api_key = <api_key>
model_version_id = <model_version_id>
base_url = <base_url>
inference_url = (
f"${base_url}/models/{model_version_id}/proxy/v1/transcript"
)
headers = {"Authorization": f"Bearer {api_key}"}
files = {
"file": (
"file_name.mp3",
open("/path/to/audio_file", "rb"),
"audio/wav", # Adjust content type if needed
)
}
response = requests.post(f"{inference_url}", headers=headers, files=files)
Response Format
2.6 Text To Speech
Endpoint
POST <API_HOST>/models/<model_version_id>/proxy/generate-speech
Usage example
import requests
api_key = <api_key>
model_version_id = <model_version_id>
base_url = <base_url>
inference_url = (
f"${base_url}/models/{model_version_id}/proxy/v1/generate-speech"
)
headers = {"Authorization": f"Bearer {api_key}"}
# get the schema of the model, each tts model has its own schema
schema = requests.get(f"{inference_url}/schema", headers=headers)
# based on the schema, you create the post request with the supported params
Example response:
[
{
"desc": "Hey, how are you doing today?",
"label": "Prompt",
"name": "prompt",
"required": true,
"type": "string"
},
{
"desc": "A female speaker with a slightly low-pitched voice",
"label": "Speaker Description",
"name": "description",
"required": true,
"type": "string"
}
]
Request Body Format
The request body should be in the following format. Use the fields names as received in the schema:
Response Format
The received audio is base64 string
2.7 Text To Image
Endpoint
POST <API_HOST>/models/<model_version_id>/proxy/generate-image
Usage example
import requests
api_key = <api_key>
model_version_id = <model_version_id>
base_url = <base_url>
inference_url = (
f"${base_url}/models/{model_version_id}/proxy/v1/generate-image"
)
headers = {"Authorization": f"Bearer {api_key}"}
payload = {
"prompt": "A man walking on the moon",
"num_inference_steps": 20,
"high_noise_frac": 8,
}
response = requests.post(f"{inference_url}", headers=headers, json=payload)
Response Format
The received image is base64 string
2.8 Translation
Endpoint
POST <API_HOST>/models/<model_version_id>/proxy/translate
Usage example
import requests
api_key = <api_key>
model_version_id = <model_version_id>
base_url = <base_url>
inference_url = (
f"${base_url}/models/{model_version_id}/proxy/v1/translate"
)
headers = {"Authorization": f"Bearer {api_key}"}
payload = {"text": "A man walking on the moon"}
response = requests.post(f"{inference_url}", headers=headers, json=payload)
Response Format
2.9 Reranking - Embedding - Classification
Usage example
import requests
api_key = <api_key>
model_version_id = <model_version_id>
base_url = <base_url>
url = (
f"${base_url}/models/{model_version_id}/proxy/v1"
)
headers = {
"Authorization": f"Bearer {api_key}",
}
# embedding
embed_payload = {"inputs": "What is Deep Learning?"}
embed_response = requests.post(f"{url}/embed", headers=headers, json=embed_payload)
# re-ranking
rerank_payload = {
"query": "What is Deep Learning?",
"texts": ["Deep Learning is not...", "Deep learning is..."],
}
rerank_response = requests.post(f"{url}/rerank", headers=headers, json=rerank_payload)
# classify
classify_payload = {"inputs": "Abu Dhabi is great!"}
classify_response = requests.post(
f"{url}/predict", headers=headers, json=classify_payload
)
3. Classical ML Models
3.1 API Endpoint
Endpoint
POST <API_HOST>/models/<model_version_id>/proxy/predict
Usage example
import requests
api_key = <api_key>
model_version_id = <model_version_id>
base_url = <base_url>
inference_url = (
f"${base_url}/models/{model_version_id}/proxy/v1/predict"
)
headers = {"Authorization": f"Bearer {api_key}"}
payload = [1, 2, 3]
response = requests.post(f"{inference_url}", headers=headers, json=payload)
Response Format
{
"data": [83.4155584413916, 209.9168121704531],
"meta": {
"input_schema": [
{
"tensor-spec": {
"dtype": "float64",
"shape": [-1, 10]
},
"type": "tensor"
}
],
"output_schema": [
{
"tensor-spec": {
"dtype": "float64",
"shape": [-1]
},
"type": "tensor"
}
]
}
}
4. Advanced options
Timeout
By default, requests have a timeout of 120 seconds.
This timeout can be adjusted on a per-request basis using the header OICM-Request-Timeout. The value should be the request timeout in seconds.
import requests
requests.post(endpoint, json=data, headers={
"Bearer": api_key,
"OICM-Request-Timeout": "300"
})
Best Practices
- Always store API tokens securely
- Use appropriate timeout values based on your use case
- Monitor token expiration dates and rotate them as needed
- Use system messages effectively for text generation tasks
- Test different temperature and top-p values to find the optimal settings for your use case
Troubleshooting
- If a request fails, check the token's validity and expiration
- Ensure the model version ID is correct
- Verify that the request format matches the endpoint specifications
- Check if the token has the necessary permissions for the requested operation